| 【精选】汇编学习教程:bx的作用 | 您所在的位置:网站首页 › 汇编 inc dec › 【精选】汇编学习教程:bx的作用 |
【精选】汇编学习教程:bx的作用
|
引言
在上篇博文中,我们已经熟悉了解如何编译、连接并运行一个程序,对MSAM工具和LINK工具的使用也已经掌握。那么从本片博文开始,也就意味着工具类的学习告此段落,下面将会是汇编语言开发方面的讲述。 本篇博文的学习目标: 1、学习 [bx] 格式的意义 2、区分Debug与MASM编译器对指令的不同处理 3、编码感受 [bx] 的用法 目标一定,就让我们赶快开始本篇的学习吧! BX寄存器我们知道8086CPU中有四个通用寄存器:AX、BX、CX、DX。 在之前的学习中我们一直接触的都是AX,比如使用AX对段寄存器赋值。那么接下来,我们将逐渐接触到BX、CX、DX他们三个的其他特殊用途,现在我们先学习BX寄存器的特殊用法。 [BX]的意义对于[...]格式,实际上我们并不是很陌生,在前几篇系列的博文中,我们知道使用DS:[idata]的形式来访问内存,idata这里表示为一个立即数(常量),对应的是相对于DS数据段的偏移。比如 mov ax,[0],意思为将内存地址为ds:0下的字单元数据送入AX寄存器内。 那么,[bx]实际上和[idata]是相同的作用,都是和DS配合进行内存的访问。 比如: mov ax,[bx] 意思为:将内存地址ds:bx下的字单元数据送入AX寄存器中。此时,BX寄存器中的内容就是相对于DS数据段的偏移。 假如此时BX寄存器内容为0,那么 mov ax,[bx] 就等同于 mov ax,[0];BX寄存器内容为1,那么 mov ax,[bx] 就等同于 mov ax,[1]。 你可能会好奇,为什么会存在[bx]?不是已经有了[idata]了么! 之所以要有[bx],是为了方便在程序中便捷的寻址。idata就是一个常量数字,一旦写进代码它就是固定的数字,那么在运行中就无法做到动态寻址,除非你修改代码,否则一直寻的都是一处固定的内存单元地址。 BX寄存器的值则是可以随时改变的,也就意味着 [bx] 的形式可以做到一个动态寻址,而不是像 [idata]这样写死的无法改变。这样,我们通过在代码中动态修改BX寄存器的值,就可以达到随心所欲的动态寻址。 Debug与MASM的区别Debug工具和Masm工具它们两个都是DOS系统下的程序,Debug工具是调式程序,可以直观的感受程序每一步执行给寄存器或者内存空间带来的变化,Masm工具是编译程序,可以将源程序文件编译成中间文件。 很显然,它们两个在功能上就有很大的区别。不过本篇博文中我们主要讲述的是 [bx],所以当然要谈谈针对 [...]的格式,它们两个之间的区别。 Debug中的 [...]还记得如何在Debug下通过 [...]形式来访问内存吗?现在我们就来复习一下: Debug下,我们使用A命令以汇编指令的形式向内存中写入机器码 以 [idata] 的形式来进行内存访问 例如:mov ax,[0] 这里我们准备一份代码: mov ax,2000H mov ds,ax mov ax,[0]很简单,将内存地址 2000H:0H下的字单元数据送入AX寄存器中。我们先使用A命令将这三条汇编指令写入内存:
然后我们使用U命令,查看一下内存中指令语句的形式:
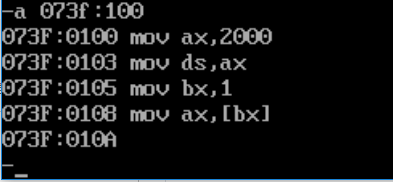
基本和我们使用A命令输入的语句保持一致,那么下面,我们使用 [bx] 的形式来再看一下,使用A命令将下面几条汇编指令写入内存: mov ax,2000H mov ds,ax mov bx,1 mov ax,[bx]
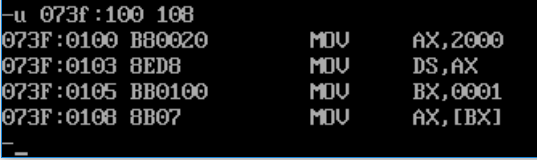
然后使用U命令,查看内存中的汇编语句形式:
还是基本和A命令写入的格式保持了一致,并未变化。 下面,我们就使用T命令来执行一下:
我们可以看到 [bx] ,bx寄存器值为1,ds:[bx]能够准确访问到了内存地址 2000H:1H下的字段元数据,等效于 [1]的形式。 那么我们就能得出结论,Debug中 [idata] 和 [bx] 这两种形式并无差别,起到的作用都是等效的。 Masm中的 [...]看完了Debug,那么我们来看看Masm工具会对这两种形式有何不同的解释呢? Masm是编译器,所以这次我们需要在Nodepad++中写代码了。还是上面的汇编语句,首先我们先看 [idata]的表现。新建文件 s2.asm,并在NodePadd++中打开:
这里要注意提醒的是: s2.asm文件要和Masm工具在同一目录下源程序中一定要定义CS代码段不要忘记写上程序结束返回写完源程序后保存一下,就可以使用Masm工具和Link工具生成可执行文件:
下面就来使用Debug加载一下可执行程序文件:
进入Debug后,我们先不急着执行,我们先使用U命令来查看一下,加载进内存中的汇编指令是什么样子呢?会不会和源程序中的汇编指令保持一致呢?
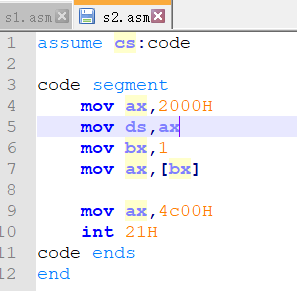
哦豁!注意看画红线的部分,我们记得这条语句原本的样子是:mov ax,[0],结果加载进内存中怎么是:mov ax,0?这是怎么回事呢? 究其原因,却是Masm编译器的问题。 Masm工具是无法识别源程序中 [idata] 的格式,碰到 [idata] 的格式便会把它当作常量来对待。[idata] 在Masm工具看来,就是常量 idata。所以我们源程序中的mov ax,[0],编译之后便变成了mov ax,idata。 那么现在,我们换上第二份代码,来看看Masm编译器是如何看待 [bx]的格式。我们修改代码如下:
我们将s2.asm源程序文件编译连接,然后将可执行程序使用Debug加载进内存中,使用U命令来查看此时内存中的汇编指令:
OK,这次我们发现是正常的mov ax,[bx],说明Masm编译器是可以正确识别并编译 [bx]的格式。 小结那么现在,我们可以对Debug和Masm的区别做一个总结: 在Debug工具中,可以准确识别 [idata] 和 [bx] 两种不同的格式; 在Masm编译器中,则会将 [idata] 的格式看做常量 idata,例如 mov ax,[idata],编译后则是 mov ax,idata。对于 [bx] 的格式,则会做到准确识别。 我们已经明白了两者的不同,那么我们再来进行深入探究:任何情况下,Masm编译器都会将 [idata] 的格式看做常量 idata 吗? 光靠脑袋猜想是不行的,我们需要亲自动手去验证。已知,mov ax,[idata] ,会被编译成 mov ax,idata,那么我们写成 mov ax,ds:[idata],编译结果还会一样吗? 话不多说,我们先动手验证。修改我们的代码如下:
注意看,这里我们将 mov ax,[0] 语句修改为了 mov ax,ds:[0]。 我们将s2.asm源程序文件编译连接后,使用Debug将生成的可执行程序加载进内存中,使用命令U查看内存中的汇编指令:
哦豁,居然准确识别出来了,没有变成 mov ax,0,而是正确的语句:mov ax,[0]。 这是为什么呢?不是说Masm编译器会将 [idata] 看成常量 idata吗,只不过加了一个 ds:,结果为什么就会变了呢? 现在,我们可以揭秘了。首先我们需要明白这两种不同的写法: 1、mov ax,[idata] 2、mov ax,ds:[idata] 首先我们知道,这两种形式所阐述的意思,即所实现的功能都是相同的:将内存地址 ds:0下的字单元内容送入AX寄存器中。mov ax,[idata],实际上是 mov ax,ds:[idata] 的简略写法,CPU会默认数据段的段地址在DS寄存器中,然后使用DS寄存器中的数据和给定的偏移进行寻址。 既然两种形式表达意思一样,那么为什么还会出现不同的编译结果呢? 答案很明显,那就是Masm编译器显然不是和我们保持相同的想法和认同。在Masm看来,mov ax,[idata] 是一种弱指定,什么是弱指定?即:源程序中给出的 [idata] 可能不是数据段下的偏移地址,它还可能是代码段CS下的偏移,也可以是栈段SS下的偏移,亦或者是补充段ES下的偏移! Masm它只是个工具,说白了就是一段程序,它当然是没办法理解人类的想法。而且它还要保证编译后的程序准确度和完整度,碰到这种不知所以的弱指定 [idata],肯定不敢贸然就认为这就是某个段的偏移地址,既然无法确定,那就干脆认为哪个段的偏移地址都不是,所以就把 [idata] 当作常量来处理啦! 而 mov ax,ds:[0] 则不一样,这是强指定,什么是强指定?即:在源程序中明确的告诉编译器,我给出的 [idata] 它就是某个段下的偏移地址。 强指定的格式即为:xx:[idata],这里 ds:[0] 意思为:明确告诉编译器,[0] 是数据段DS下的偏移地址。正因如此,Masm编译器知道这就是数据段下的偏移,所以便会正确进行编译,编译结果正常。 经过上述的探讨,博主这里给出建议: 在编写源程序中,请尽量使用强指定的格式,1:可以避免编译结果出错的问题,2:增强了源程序的可读性。 本篇结束语在本篇博文中,我们主要讲述了 [bx] 格式访问内存,Debug工具和Masm工具对于 [bx] 不同的解释。此外,我们明白了为什么Masm会对 [idata] 有不同的解释,取决于弱指定和强指定。 那么在下篇博文中,我们将接触到汇编中的循环,学习CX寄存器在其中承担的角色。 感谢围观,转发分享请标明出处,谢谢! |











【本文地址】